HashMap in Java
In some situations, you need to store pairs of associated objects. For example, when counting the number of words in a text, the first one is a word, and the second one is the number of its occurrences in the text. There is a special type of collection called map to effectively store such pairs of objects. A map is a collection of key-value pairs. Keys are always unique, while values can repeat.
A good example of a map from the real world is an employee record book where employee IDs are keys and employee names are values.
Keys : Values
-----------------------
Bob : +1-202-555-0118
James : +1-202-555-0220
Katy : +1-202-555-0175Maps have some similarities with sets and arrays;
- keys of a map form a set, but each key has an associated value;
- keys of a map are similar to indexes of an array, but the keys can have any type including integer numbers, strings and so on.
Due to these reasons, you can encounter some kind of deja vu effect when learning maps.
Next, all our examples will use string and numbers as keys since using custom classes as types of keys have some significant complexity that we need to consider.
The Map interface
The Collections Framework provides the Map<K,V> interface to represent a map as an abstract data type. Here, K is a type of keys, and V is a type of associated values. The Map interface is not a subtype of the Collection interface, but maps are often considered as collections since they are part of the framework.
The interface declares a lot of methods to work with maps. Some of the methods are similar to methods of Collection, while others are unique to maps.
1) Collection-like methods:
int size()returns the number of elements in the map;boolean isEmpty()returnstrueif the map does not contain elements andfalseotherwise;void clear()removes all elements from the map.
We hope these methods do not need any comments.
2) Keys and values processing:
V put(K key, V value)associates the specifiedvaluewith the specifiedkeyand returns the previously associated value with thiskeyornull;V get(Object key)returns the value associated with the key, ornullotherwise;V remove(Object key)removes the mapping for akeyfrom the map;boolean containsKey(Object key)returnstrueif the map contains the specifiedkey;boolean containsValue(Object value)returnstrueif the map contains the specifiedvalue.
These methods are similar to the methods of collections, except they process key-value pairs.
3) Advanced methods:
V putIfAbsent(K key, V value)puts the value if the specified key is not already associated with a value (or is mapped tonull) and returnsnull, otherwise, returns the current value;V getOrDefault(Object key, V defaultValue)returns the value to which the specified key is mapped, ordefaultValueif this map contains no mapping for the key.
These methods, together with some others, are often used in real projects.
4) Methods which return other collections:
Set<K> keySet()returns aSetview of the keys contained in this map;Collection<V> values()returns aCollectionview of the values contained in this map;Set<Map.Entry<K, V>> entrySet()returns aSetview of the entries (associations) contained in this map.
This is not even a complete list of methods since Map is a really huge interface. So reading the documentation can be really helpful when using maps.
To start using a map, you need to instantiate one of its implementations: HashMap, TreeMap, or LinkedHashMap. They use different rules for ordering elements and have some additional methods. There are also immutable maps.
Immutable maps
The simplest way to create a map is to invoke the of method of the Map interface. The method takes zero or any even number of arguments in the format key1, value1, key2, value2, ... and returns an immutable map.
Map<String, String> emptyMap = Map.of();
Map<String, String> friendPhones = Map.of(
"Bob", "+1-202-555-0118",
"James", "+1-202-555-0220",
"Katy", "+1-202-555-0175"
);Now let's consider some operations that can be applied to immutable maps using our example with employeeBook.
The size of a map equals the number of pairs contained in it.
System.out.println(emptyMap.size()); // 0
System.out.println(friendPhones.size()); // 3It is possible to get a value from a map by its key:
String bobPhone = friendPhones.get("Bob"); // +1-202-555-0118
String alicePhone = friendPhones.get("Alice"); // null
String phone = friendPhones.getOrDefault("Alex", "Unknown phone"); // Unknown phoneNote that the getOrDefault method provides a simple way to prevent NullPointerException since it avoids null.
It is also possible to check whether a map contains a particular key or value by using containsKey and containsValue methods.
We can directly access the set of keys and collection of values from a map:
System.out.println(employeeBook.keySet()); // [07, 43, 98]
System.out.println(employeeBook.values()); // [Bob, James, Katy]Since it is immutable, only methods that do not change the elements of this map will work. Others will throw the UnsupportedOperationException exception. If you'd like to put or remove elements, we suggest you use one of HashMap, TreeMap or LinkedHashMap.
HashMap
The HashMap class represents a map backed by a hash table. This implementation provides constant-time performance for get and put methods assuming the hash function distributes the elements uniformly among the buckets.
The following example demonstrates a map of products where the key is the product code, and the value is the name.
Map<Integer, String> products = new HashMap<>();
products.put(1000, "Notebook");
products.put(2000, "Phone");
products.put(3000, "Keyboard");
System.out.println(products); // {2000=Phone, 1000=Notebook, 3000=Keyboard}
System.out.println(products.get(1000)); // Notebook
products.remove(1000);
System.out.println(products.get(1000)); // null
products.putIfAbsent(3000, "Mouse"); // it does not change the current element
System.out.println(products.get(3000)); // KeyboardThis implementation is often used in practice since it is highly-optimized for putting and getting data pairs.
There are different ways to create a map filled with key-value pairs. It's time to take a good look at the hash map: an effective instrument that is probably the most popular implementation of the Map interface. It provides very fast access to its elements and falls within the top ten questions asked at Java job interviews.
How does it work?
The HashMap class represents a map backed by a hash table. To understand what it is, let's start with the internal organization of HashMap.
If you look inside HashMap you will see that it's an array with buckets as its elements. The default size of such an array is 16.

What could be a "bucket" in a programming language? Actually, each bucket is a linked list, meaning there are 16 linked lists for storing key-value pairs. And each key-value pair is an element of a linked list.
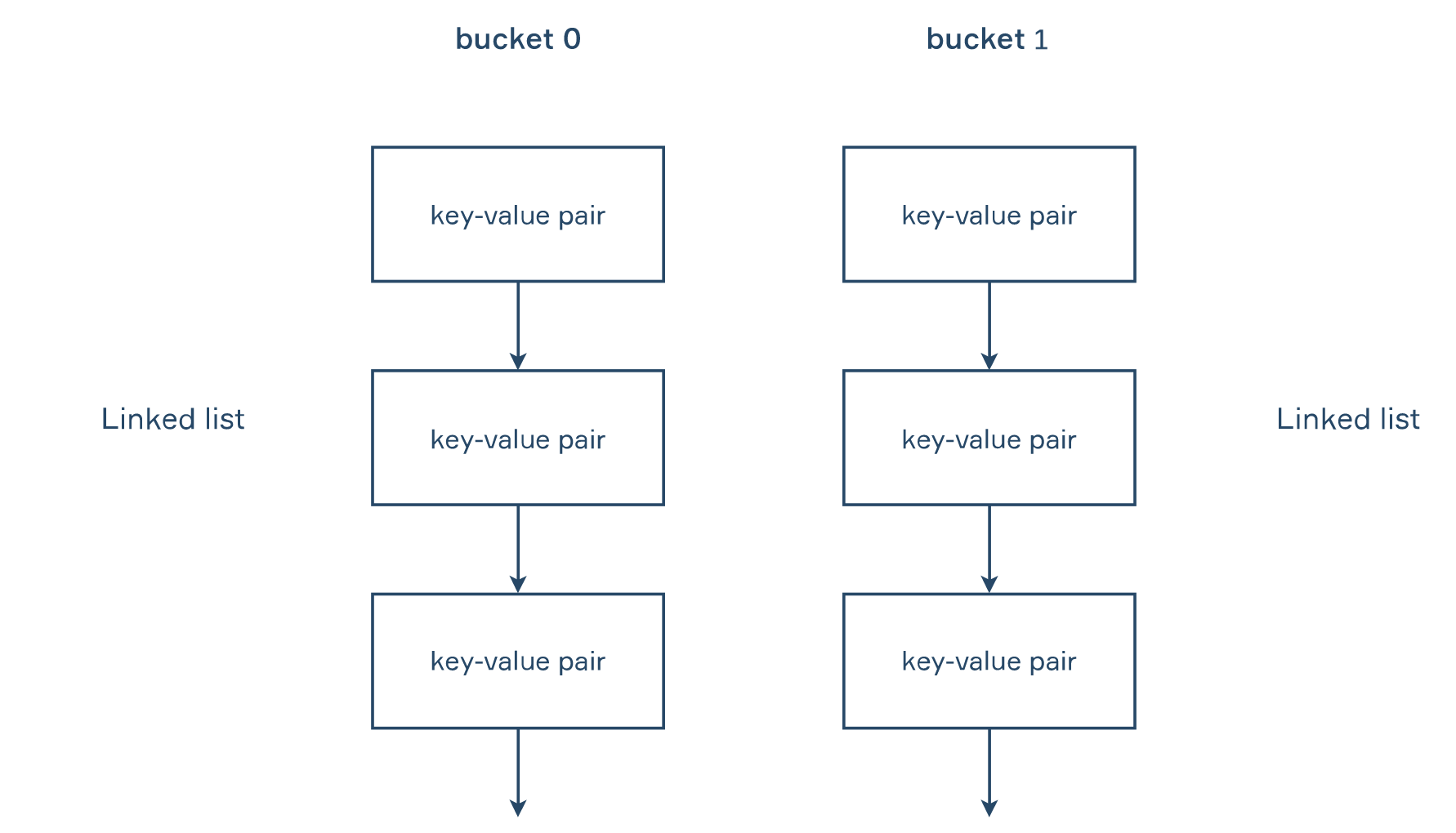
Now we need a special structure to store the key-value pairs as well. This structure is a class called Node. It has four fields: the first one is hash, then there's our key and value, and the last one contains a link to the next pair.

Now you know how HashMap looks inside and are ready to learn what is happening when you put an element in it. Any ideas on how a HashMap decides where to put your key-value pair?
Here's what happens: first, it generates the hash code of your key. Next, it generates the index of the bucket, which depends on the calculated hash.
In the formula below n is the number of buckets:
index = hash & (n - 1)Alternatively, you can calculate the index as follows:
index = hash % nIt will give the same result, but works slower than a bitwise operation. Also, you should know that n is always a power of 2. This is guaranteed by the tableSizeFor method inside the HashMap class.
First, let's think how the % operation works when n is a power of 2 and hash is a positive whole number. For clarity, we'll set n as 4:
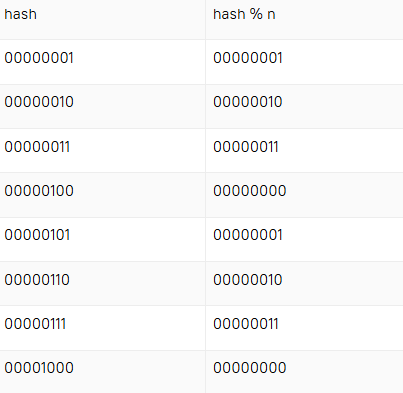
As you can see, this mod operation removes all the bits that are more significant or equal than n (here n = 00000100).
On the other hand, what happens in the bit world when you do hash & (n - 1)? Again, you remove more significant bits, becausen - 1 always looks like 00000011 (zeros followed by ones).
Now that you've mastered the theory of the HashMap organization, it's time to consider some examples.
Thanks to the hash function, this implementation provides constant-time performance for get and put methods! Constant-time means O(1) complexity.
Now that you've mastered the theory of the HashMap organization, it's time to consider some examples.
Time to play!
To get a similar debugging view: right click on the map and choose "View as" —> "Object". Then right click on the element and choose "View as" —> "Object". Clicks don't depend on each other.
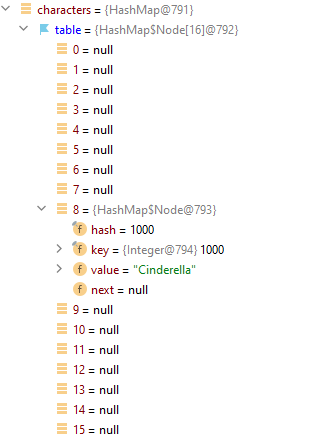
Map<Integer, String> characters = new HashMap<>();
characters.put(1000, "Cinderella");Here we've created a HashMap called characters and added Cinderella in it. There are exactly 16 buckets. The class has calculated that the index of the new bucket would be 8.
In the picture, you can see that Cinderella is the first Node of the 8th linked list. As we've said earlier, Node has four fields. In our example, the hash code and the key are the same. For Integer class hash code is the same as its value. Note that every class has different logic for calculating hash code. You can override the method hashCode as well. Also, it's good to know that it is possible to create a pair in which the key would be null. The hash code of the null-key is always zero. Now let's add more characters and see what will happen:
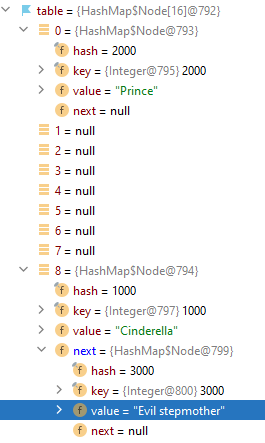
characters.put(2000, "Prince");
characters.put(3000, "Evil stepmother");
// {2000=Prince, 1000=Cinderella, 3000=Evil stepmother}
System.out.println(characters); Character Prince decided to be in the bucket with index 0. He is also the first Node in his linked list. But a stepmother can't be far away from poor Cinderella! Evil stepmother is also staying in the bucket with the number 8. As you can see, the field next in Cinderella's Node has changed. Now the field has a link to the next character, Evil stepmother. Because the Evil stepmother became the last one in this linked list, her field next has value null.
Let's try to remove an element from the characters HashMap:
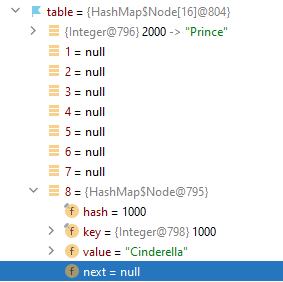
characters.remove(3000); // get rid of Evil stepmother
System.out.println(characters.get(3000)); // nullThe element Evil stepmother was deleted. Cinderella became the first and the last element of the eighth linked list again. To see the structure of your HashMap in the same way as in the pictures, you can use Debug mode in IntelliJ IDEA.
Since HashMap implements the Map interface, the methods we had discussed in the previous section can also be used. We will only look at some of them.
Getting an element by a key:
System.out.println(characters.get(1000)); // CinderellaMethod putIfAbsent:
characters.putIfAbsent(2000,"Another Prince"); // nothing happens, because there is already a Prince
System.out.println(characters.get(2000)); // PrinceUsing containsKey and containsValue to check if there is a concrete key or a value inside of HashMap:
System.out.println(characters.containsKey(1000)); // true
System.out.println(characters.containsValue("Fairy Godmother")); // falseFor the interview
Let's consider some interesting moments. Firstly, you, as a software engineer, can choose what number of buckets will be in HashMap. Remember that the initial capacity is always a power of two, even if you input something like "5".
Map<String, String> map = new HashMap<>(32);Another important point is collisions. There is always a chance of a situation when two distinct keys will generate the same hash code. This situation is called a collision.
map.put("AaAaAa","First");
map.put("BBBBBB","Second");If the two keys have the same hash code but the keys are different, the second element will be put right after the first one. In this example, keys AaAaAa and BBBBBB have the same hash code, and Node with the value First will have a link to the Node with the value Second.
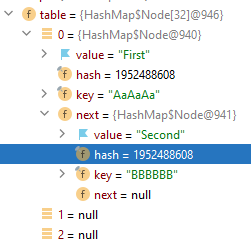
Method equals is used for checking if the two keys are different. If they are the same, the second pair will replace the first one. If there are a lot of collisions in a HashMap the complexity for get and put methods becomes O(n). Because of that, class HashMap was upgraded. Since Java 8, it provides the collision resolution mechanism. If linked lists are too long then HashMap changes their structure: all linked lists become balanced trees. The new complexity is O(log(n)).
Finally, it's important to note that HashMap can change the number of buckets. If there are too many pairs in your buckets HashMap will change its size to a bigger one. It will transfer all your previous elements to the new version of itself. That, unfortunately, will take some time. And the more elements there are, the longer transferring will take. The moment when HashMap resizes depends on its load factor. The default load factor is 0.75 and you can define a different one in the constructor: HashMap(int initialCapacity, float loadFactor). When the number of entries in HashMap exceeds a certain threshold calculated as current capacity * load factor, HashMap increases its capacity.
More about comparisons
When you add an object to HashMap, the hash code in the Node structure is calculated only once and can't be changed afterwards. Let's consider a simple example: you want to find an object by a key (in other words, perform a get operation):
- First, your own hash code of the key will be compared with the hash code in the
Nodestructure. - Only if the hash codes match, the
equalsmethod will be executed for the keys for the final decision.
Here comes a tricky moment. You've created a HashMap and filled it:
Map<BigComplexClass, Integer> map = new HashMap<>();
map.put(bigKey, 123); // bigKey is an instance of BigComplexClassThen, you update the state of bigKey (for example, a field in it). What will happen if you try map.get(bigKey)? You won't find it in a map. And these are the two reasons why: you either miss it because the updated hash code of bigKey doesn't match the hash code in Node, or, if the hash code hasn't changed, the second step with the equals method will give "false".
When to use it?
The short answer to the question in the title is — if you need to store key-value pairs and want the mutable implementation of the Map interface. HashMap class is often used in practice since it is highly optimized for accessing elements. Also, iteration over HashMap is highly efficient.
And what about the disadvantages? Well, nobody's perfect. There is no way to avoid collisions. The size of HashMap may increase so that it will take some time to transfer all the elements.
At last, remember, that HashMap class makes no guarantees as to the order of the map. It also does not guarantee that the order will remain constant over time.
