Java HashSet
This topic introduces HashSet, the most commonly used implementation of the Set interface. The class embodies a mathematical set and is designed for storing unique elements. We will cover its features, frequently used methods, constructors, and limitations.
HashSet behavior
HashSet is a collection designed for storing unique objects while offering high-performance access. It's not suitable for storing duplicate elements. The example below illustrates basic HashSet functionality.
import java.util.HashSet;
import java.util.Set;
public class HashSetDemo {
public static void main(String[] args) {
Set<String> set = new HashSet<>();
set.add("J. Gosling");
set.add("J. Bloch");
set.add("J. Gosling");
set.add("B. Kernighan");
set.add("J. Bloch");
set.add("J. Gosling");
System.out.println(set); // output: [J. Gosling, B. Kernighan, J. Bloch]
}
}Let's discuss some practical and essential characteristics of HashSet. Elements in a HashSet are inserted based on their content hash code, which means that HashSet does not maintain the insertion order. While searching through the data is fast, the class does not offer a sorting method. It provides constant-time performance for basic operations such as add, remove, contains, and size. HashSet contains unique elements, which may include a single null value. It's worth noting that HashSet is not synchronized and, therefore, not thread-safe. While it's possible to make HashSet thread-safe, it is beyond the scope of this discussion. For further details, we recommend consulting the official documentation. To summarize, here is a list of essential facts about HashSet:
HashSetcontains only unique elements — no duplicates allowed;- A set can include a single null value;
- Elements are stored based on hashing;
- The insertion order is not maintained — unordered;
- There is no sort method — unsorted;
- Search operations are fast;
- Not synchronized — hence, not thread-safe.
Constructors
The two fundamental constructors for HashSet are as follows:
public HashSet()public HashSet(Collection<? extends E> c)
For the first constructor, you can create an empty set. Initially, since no elements have been added, the output will display an empty set, represented as []. To populate the set, you can employ the add or addAll methods.
Set<String> set = new HashSet<>();
System.out.println(set); // output: []For the second constructor, which can be described as a copy or conversion constructor, a new set is created that contains the elements from a specified collection. In the example below, the collection is a list. Since a set cannot contain duplicate elements, adding items that are already present will have no effect.
List<String> list = List.of("Mars","Earth", "Jupiter", "Mars");
Set<String> set = new HashSet<>(list);
System.out.println(set); // output: [Earth, Mars, Jupiter]Alternatively, you could accomplish the same outcome as in the above example by taking an extra step: first, create an empty set and then use the addAll method. However, it is generally preferable to utilize the parametrized constructor, as demonstrated earlier. The longer version is illustrated below for your reference.
List<String> list = List.of("Mars","Earth", "Jupiter", "Mars");
Set<String> set = new HashSet<>();
set.addAll(list);
System.out.println(set); // output: [Earth, Mars, Jupiter]Methods
Now let's delve into the primary HashSet methods that you can utilize in your applications. We'll start with the add() method. Methods that operate by searching for elements, including this one, typically have O(1) time complexity. The methods we'll review are as follows:
add(E e)— Adds the element if it's not already present and returnstrue.contains(Object o)— Returnstrueif the set contains the specified element.remove(Object o)— Removes the element from the set if it is present and returnstrue.isEmpty()— Returnstrueif the set has no elements.size()— Returns the number of elements in the set.toArray()— Returns all the elements in the set as an array.clear()— Removes all elements from the set.iterator()— Returns an iterator for the elements in this set.
To utilize the add() method, start by creating a set. You can then add unique elements to this new set. Attempting to add a duplicate element will result in a false return value.
Set<String> set = new HashSet<>();
set.add("Mars"); // true
set.add("Earth"); // true
set.add("Jupiter"); // true
set.add("Mars"); // false
// set contains [Mars, Earth, Jupiter]HashSet doesn't just support String, as you can use it with various wrapper classes:
Set<String> set1 = new HashSet<>();
set1.add("Venus");
Set<Boolean> set2 = new HashSet<>();
set2.add(true);
Set<Character> set3 = new HashSet<>();
set3.add('G');
Set<Byte> set4 = new HashSet<>();
set4.add((byte) 7);
Set<Short> set5 = new HashSet<>();
set5.add((short) 5);
Set<Integer> set6 = new HashSet<>();
set6.add(9123);
Set<Long> set7 = new HashSet<>();
set7.add(34000L);
Set<Float> set8 = new HashSet<>();
set8.add(4.5F);
Set<Double> set9 = new HashSet<>();
set9.add(345678923D);The add() method isn't the only way to populate a HashSet. Starting from Java 9, you can use the static method of() from the Set interface to create an immutable set. Adding any elements to such a set will throw an UnsupportedOperationException:
Set<String> set = Set.of("Mars","Earth", "Jupiter");
set.add("Venus"); // UnsupportedOperationExceptionDuplicate elements when using of() will result in an IllegalArgumentException.
Set<String> set = Set.of("Mars","Earth", "Jupiter", "Mars"); // IllegalArgumentExceptionHashSet doesn't provide a method to get an element. Instead, there is a method that checks for the presence of an element. We use the contains() method, as seen below. This example uses Set.of() to build the HashSet.
Set<String> set = new HashSet<>(Set.of("J. Gosling"));
set.contains("J. Gosling") // output: trueOwing to its optimized internal structure, the contains() method in a HashSet can operate significantly faster than its counterpart implementing the List interface. For instance, the contains() method in an ArrayList scans through each element to find a match, resulting in a time complexity of O(n). However, the contains() method in a HashSet is able to locate the correct element efficiently—generally in constant time, or O(1). This same performance advantage extends to the remove() method in a HashSet as well.
Moving on, let's discuss how HashSet manages the removal of elements. Unlike collections that implement the List interface, HashSet does not provide a get() method for retrieving elements. However, it offers two convenient methods for element removal. The first is remove(), which removes a specific element if it is present in the set. The second method is clear(), which is used for purging all elements from the set.
We can always check the current size of a set with the size() method, which returns the size as an integer value. Also, checking for an empty set is just as easy with the isEmpty() method, which returns true when the set is empty.
Take a look at this example which illustrates the use of the methods we just discussed:
Set<String> set = new HashSet<>();
set.add("J. Gosling");
set.add("J. Bloch");
set.add("B. Eckel");
set.remove("J. Gosling"); // output: true
set.size(); // output: 2
set.clear(); // removes all elements
set.isEmpty() // output: trueThe next method we'll examine is toArray() which is used for converting a set into an array. This method comes in two flavors. The first version does not require any arguments and returns an array of Object types. The second version, on the other hand, accepts one argument — indicating the type of array you wish to return — and provides an array of that specified type. The example code below demonstrates these two different usages. The first returns only Object type. The second returns the runtime type as provided — String[]. Depending on the application, you can use any wrapper type.
import java.util.HashSet;
import java.util.Set;
class Set2Array {
public static void main(String[] args) {
Set<String> set = new HashSet<>();
set.add("J. Gosling");
set.add("J. Bloch");
set.add("B. Eckel");
Object[] object = set.toArray();
System.out.println("Array type: Object");
for (Object name : object) {
System.out.println(name);
}
String[] specified = set.toArray(new String[0]);
System.out.println("\nArray type <T> T[]: String ");
for (String name : specified) {
System.out.println(name);
}
}
}Here we show the output of this program illustrating the two types of the toArray method.
Array type: Object
J. Gosling
B. Eckel
J. Bloch
Array type <T> T[]: String
J. Gosling
B. Eckel
J. BlochThe iterator() method returns an iterator over the elements in a set. Note that the elements are returned in no specific order. Additionally, the iterator is "fail-fast," meaning it throws a ConcurrentModificationException if the collection is modified during iteration. This exception is thrown to indicate that the collection should not be changed while being iterated over, except through the iterator's own remove() method. The example program below demonstrates this behavior: it operates as expected when simply printing output, but using the remove() method of the HashSet in conjunction with its iterator() method will result in a ConcurrentModificationException.
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
class hashSetIterator {
public static void main(String[] args) {
Set<Integer> integers = new HashSet<>();
integers.add(1);
integers.add(2);
integers.add(3);
Iterator<Integer> iterator = integers.iterator();
while (iterator.hasNext()) {
Integer number = iterator.next();
System.out.print(number + " "); // output: 1 2 3
//integers.remove(number); // ConcurrentModificationException
}
}
}From JavaDoc:
The iterators returned by this class's iterator method are fail-fast: if the set is modified at any time after the iterator is created, in any way except through the iterator's own remove method, the Iterator throws a ConcurrentModificationException. Thus, in the face of concurrent modification, the iterator fails quickly and cleanly, rather than risking arbitrary, non-deterministic behavior at an undetermined time in the future.Limitations
Up to this point, we have used HashSet exclusively with predefined classes such as String and Integer. However, many use cases require the storage of objects based on user-defined classes. We have yet to address this topic, in part because of its added complexity. Storing such objects can be safe only if managed properly. Precise checks and comparisons are necessary to determine object equality when working with user-defined classes. Thread safety is another issue; if multiple threads need to access the HashSet, you must implement synchronization mechanisms. Lastly, HashSet relies on internal hash functions. If these are not well-designed, it could result in performance problems. Specifically, a poor distribution of elements' hash codes could lead to degraded performance.
HashSet internals
Inside the HashSet class is a private HashMap<E, Object> map field instantiated when calling the HashSet constructor – all elements stored as keys. When you add an element to a HashSet, you add it to an internal HashMap. Moreover, when you iterate over HashSet elements, you are iterating over the keySet() of the HashMap. Let's analyze the add() method source code seen below:
// Java 17public boolean add(E e) { return map.put(e, PRESENT) == null;}
The add() method accepts an object, puts a key-value pair to the HashMap, and checks the return value of that operation. If null, there was no pair with such a key in a HashMap, and the add() method returns true. If a key is present, the add() method returns false, meaning the element will not be added to the set.
Studying the code above, you might have asked yourself a question. We pass only one object to the add() method, passed to the HashMap as a key, but where did the PRESENT variable come from? The answer is there is another HashSet field: private static final Object PRESENT = new Object(). It is used as a dummy object in the internal HashMap as the value of the entry. This relationship is illustrated below.

HashSet and user-defined classes
We will examine how user-defined data types are used in a HashSet to guarantee accurate, dependable, and efficient results. These data types, when created, declare their behavior and exhibit unique characteristics. Unlike wrapper data types, user-defined types usually have multiple fields, giving newly created objects distinguishable attributes of their own depending on their constructor initialization. For this reason, we must take extra precautions when working with user-defined types and HashSet, as we are no longer just working with a field in a wrapper type.
As we know, the Object class is the root of the class hierarchy; therefore, Object is the superclass (parent) of all derived classes. The Object class has two methods crucial to how HashSet works when dealing with user-defined types. These are equals() and hashcode(), which combine to make object comparisons in harmony. As defined in class Object (parent), these two methods do not always meet the requirement to check whether two or more objects (child) have the same values. The reason is inadequate methods implementation when you invoke Object default methods. The solution is to override the equals and hashCode methods. If you don't override these two methods, you are invoking the default methods of the Object (parent) class, giving you inefficient results or, worse, possibly corrupting HashSet operations.
Let's look at some potential issues that could occur while using HashSet. The user-defined class, Person, provided below is used here to illustrate how HashSet relies on the correct overriding of methods equals() and hashCode(). We can consider the content of class Person to be its two fields: String name and Integer id. As we will see shortly, HashSet should rely on the content; name and age in Person, of elements to check equality. However, the default equals() method does not do this, as it only checks the references of two objects to verify their equality. This means that two objects are equal only if they refer to the same memory location. We want to check equality by comparing the logical content of each element: name and age. The hashCode method needs to be overridden to satisfy the contract — if two objects are equal according to the equals() method, then hashCode should generate the same hash code. The Person class listed below, which has no overridden methods, is used in the code examples.
class Person {
private String name;
private Integer age;
public Person(String name, Integer age) {
this.name = name;
this.age = age;
}
// Getter and Setter
@Override
public String toString() {
return "Person{" +
"Name= '" + name + "' " +
"Age= '" + age + "'}";
}
}Let's use the program below to add two elements to a HashSet — persons. Here we want to illustrate the significance of correctly implemented equals() and hashCode() methods when using HashSet. Since unique elements are inserted into a HashSet, we must be sure our equality checks are accurate. We don't want to add duplicate elements. Person references p1 and p2, creating two objects with the same logical information. When checking equality, we expect these to be equal since they have the same name and age. Remember that Person currently uses the default equals() and hashCode() methods. Notice that p1 and p2 are logically equal.
import java.util.*;
public class HashSetDemo {
public static void main(String[] args) {
Person p1 = new Person("Gosling", 68);
Person p2 = new Person("Gosling", 68);
Set<Person> persons = new HashSet<>();
persons.add(p1);
persons.add(p2);
System.out.println("hashCode: " + p1.hashCode() +
" " + p2.hashCode());
System.out.println("p1.equals(p2): " + p1.equals(p2));
System.out.println(persons);
}
}As a result, running this program provides us with the following output – see below. Is this what we want? The answer is no. Let's analyze our current scenario to understand what is going on. The output shows that p1 and p2 are not equal, and neither are their hash codes. So, with the current equality check, they are incorrectly added to the HashSet. Visually comparing the fields' name and age, we see the contents are the same; therefore, only one person should have been added to the set.
hashCode: 312116338 453211571
p1.equals(p2): false
[Person{Name= 'Gosling' Age= '68'}, Person{Name= 'Gosling' Age= '68'}]Keep in mind, your hash codes may show different values.
The default equals() method is shown below.
public boolean equals(Object obj) {
return (this == obj);
}Here the default equals() method is essentially comparing two memory addresses. There is no check for any unique content objects may contain, such as in fields name and age. We need to override the equals() method to remedy this undesirable behavior. Keep in mind that our goal here is to have a dependable HashSet. Let's look at an equals() method containing additional code for more comprehensive checks.
@Override
public boolean equals(Object o) {
if (this == o) {
return true;
}
if (o == null || getClass() != o.getClass()) {
return false;
}
Person person = (Person) o;
return name.equals(person.name) && age.equals(person.age);
}First, as in the default method, the current object instance is compared with the passed object. Next, we check for a null value and also whether the two classes are not equal. Finally, we cast the passed object to Person and return the comparison to determine the object's equality based on the logical fields name and age.
Let's run the HashSetDemo program with the overridden equals() method in class Person to see how it affects the HashSet result. Our new equals() method now correctly compares p1 and p2 as true. However, the hash codes were not affected as they were still checked as not equal. Also, we are still adding two logically identical entries to the HashSet, which is not what we want.
hashCode: 312116338 453211571
p1.equals(p2): true
[Person{Name= 'Gosling' Age= '68'}, Person{Name= 'Gosling' Age= '68'}]Keep in mind, your hash codes may show different values.
What we have left to do with the class Person in order to reliably use it with a HashSet, and indirectly HashMap, is override its hashCode method. Note that if two objects are equal when using the equals() method, then using the hashCode method must generate the same integer value. Always override hashCode() whenever you override equals(). When writing a good hashCode method, we should strive to produce different hash codes for unequal instances. This will improve the performance of the HashSet.
Let's use the hashCode() method in the Person class below to see its effect on HashSetDemo. Here we are using Objects.hash(name, age) to return a hash code. The advantage of this approach is that we can use an arbitrary number of fields to calculate a hash code for an object. In our example, we are using name and age from the Person class. This approach has an average performance and can be used in routine applications, but you can write your own or use your IDE to generate one with better performance.
@Override
public int hashCode() {
return Objects.hash(name, age);
}After adding the overridden hashCode method to the class Person and running HashSetDemo, we get the result below. Notice that this time, the hash codes are the same, and p1 and p2 are equal, and finally, the set only has one entry — as expected. We can now see that to have a reliable result using HashSet, it is crucial to override the equals() and hashCode() methods of user-defined classes that we provided to HashSet.
hashCode: -1985493692 -1985493692
p1.equals(p2): true
[Person{Name= 'Gosling' Age= '68'}]Keep in mind, your hash codes may show different values.
In the preceding example, we witnessed the need to correctly implement equals() and hashCode methods within a class to be used with the HashSet. These methods were designed to be overridden as they have a general contract that must be kept by the class doing the overriding. Class HashSet depends on accurate equality checks, and its efficiency depends on good hash functions implemented in hashCode.
HashSet time complexity
Remember that HashSet is based on a HashMap backed by a hash table.
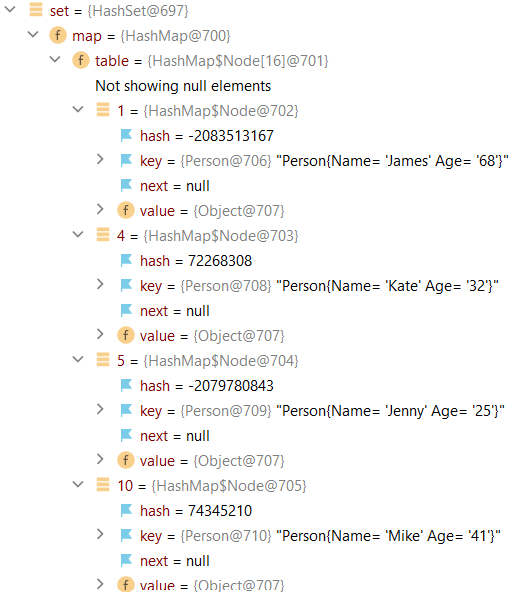
The illustration below shows the results of a hash function when interacting with a hashSet — this is considered a good result. Let's add multiple Person objects to a hashSet, each with its unique hash code. Here, we can expect a time complexity of O(1) due to its uniform distribution across the table indexes. This constant-time performance is true for basic HashSet operations — add, remove, contains, and size. If we have no collisions, then element insertion and retrieval remain constant. As we fill the table, collisions increase proportionally to the increasing load — the number of elements divided by the number of buckets. With increasing collisions, we have more table look-ups, which lowers performance towards O(n) i.e. linear-time. To prevent HashSet performance from degrading, rehashing increases the table size and then copies all the elements to this larger table. This occurs when the load reaches a specified threshold which is referred to as it's load factor. Since Java 8, the collision resolution mechanism changes the structure to a balanced tree, providing a logarithmic-time complexity of O(log(n)). The table below shows that each object has a unique index (bucket) and hash code.
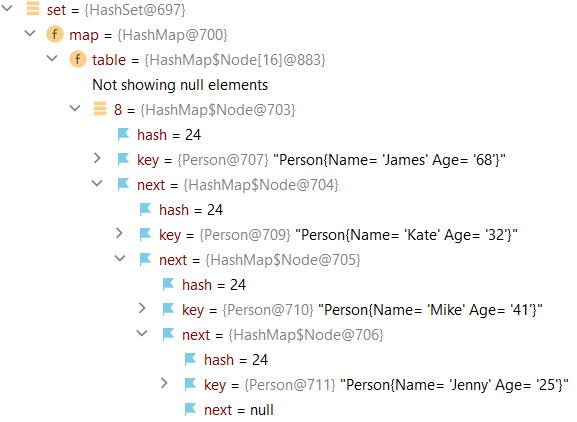
The following example illustrates the result of a badly implemented hashCode method that always returns int 24. As we can see, all the Person objects end up in the same index (bucket 8) as a linked list. Here we see the worst-case time complexity behavior of O(n). We must implement a good hashing function to achieve the best-case complexity of O(1).
Constructor tuning
HashSet has two advanced constructors as shown below.
HashSet(int initialCapacity)HashSet(int initialCapacity, float loadFactor)Both constructors here create an empty set with a backing HashMap instance. When using the first, you specify the initialCapacity; the default load factor is 0.75. The second version allows you to set the initialCapacity and the loadFactor. It is usually not necessary to set these configuration parameters as the basic constructors fulfill most requirements you may have. Finding the correct balance can be tricky and should be carefully implemented. Experimenting with these parameters can be a helpful learning tool.
Conclusion
To understand how class HashSet works internally, we must always remember that it depends on the HashMap class, which is backed by a hash table. When you add an element to a HashSet, you add it to an internal HashMap as well. The key to understanding HashSet internals lies in your grasp of HashMap.
When HashSet has to deal with user-defined classes as extensions of class Object, you have to ensure that the your user-defined objects obey certain method contracts, namely, equals() and hashCode(). HashSet depends on the correct overriding of these two methods in order to function properly. As a rule, you must override hashCode() when you override equals(). Unequal hash codes should be assigned to unequal user-defined objects as best as possible.
The time complexity of HashSet basic operations – add, remove, contains, and size – is O(1), with a good hashing function when used with user-defined objects. As collisions increase, the time complexity degrades toward the O(n) spectrum. Java 8 introduced a balanced tree to better resolve collisions. This algorithm provides a much faster time complexity of O(log(n)).
