SQL GROUP BY statement
General form
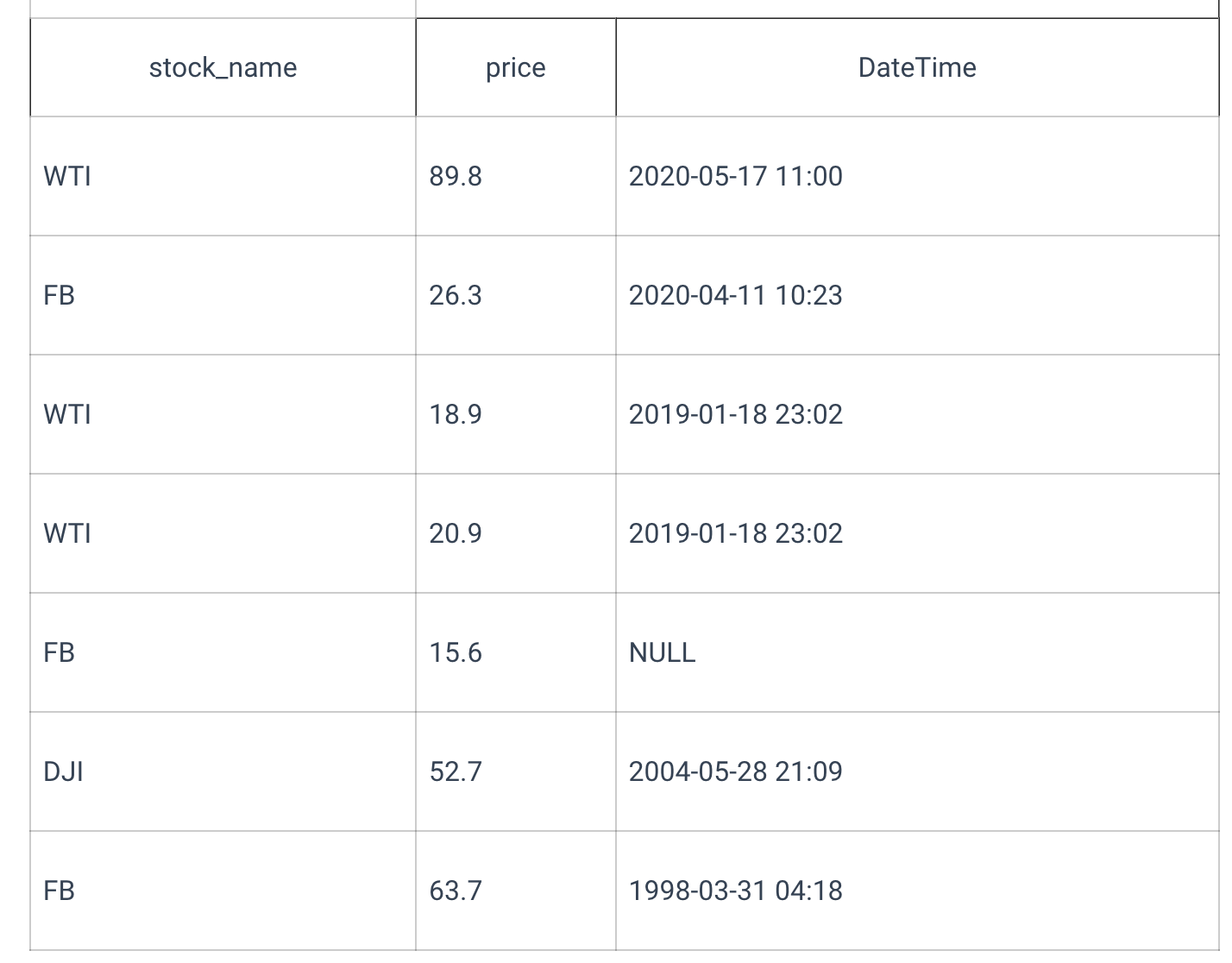
You have a table named stocks with historical prices. You need to compute aggregate values for multiple categories.
For such a task, use the GROUP BY statement:
The output would look like this:
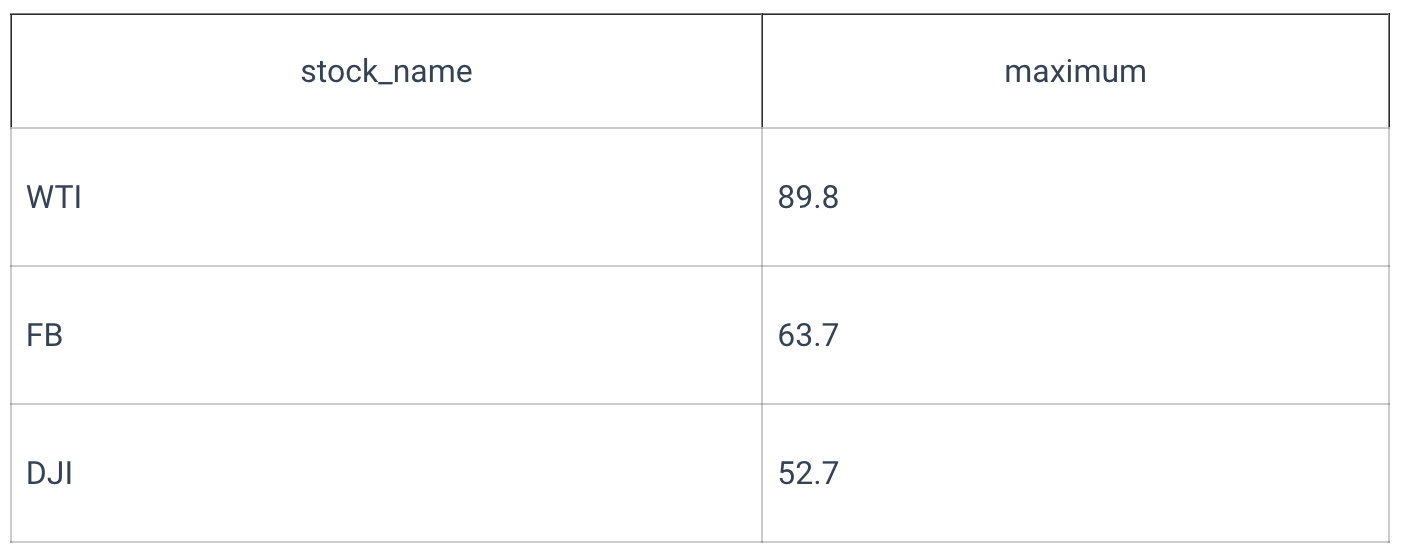
In the GROUP BY clause, specify a column's name from the table. Every unique value from this column will result from every utilized aggregate function from the SELECT block. Rows corresponding to this value will be taken as an input. It's possible to group things by a computed value not currently present in a table.
Nothing forbids the use of more than one aggregate function. Returned values can be completely independent of each other:
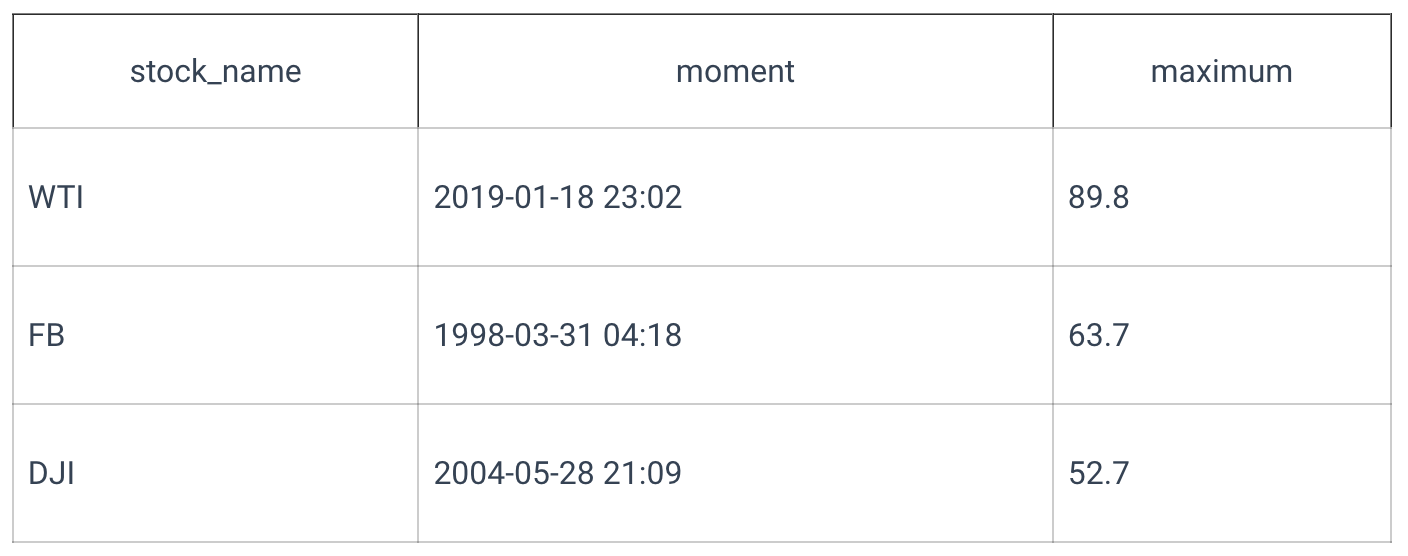
If there are several columns in the GROUP BY clause, each unique combination of values from these columns will be aggregated separately.
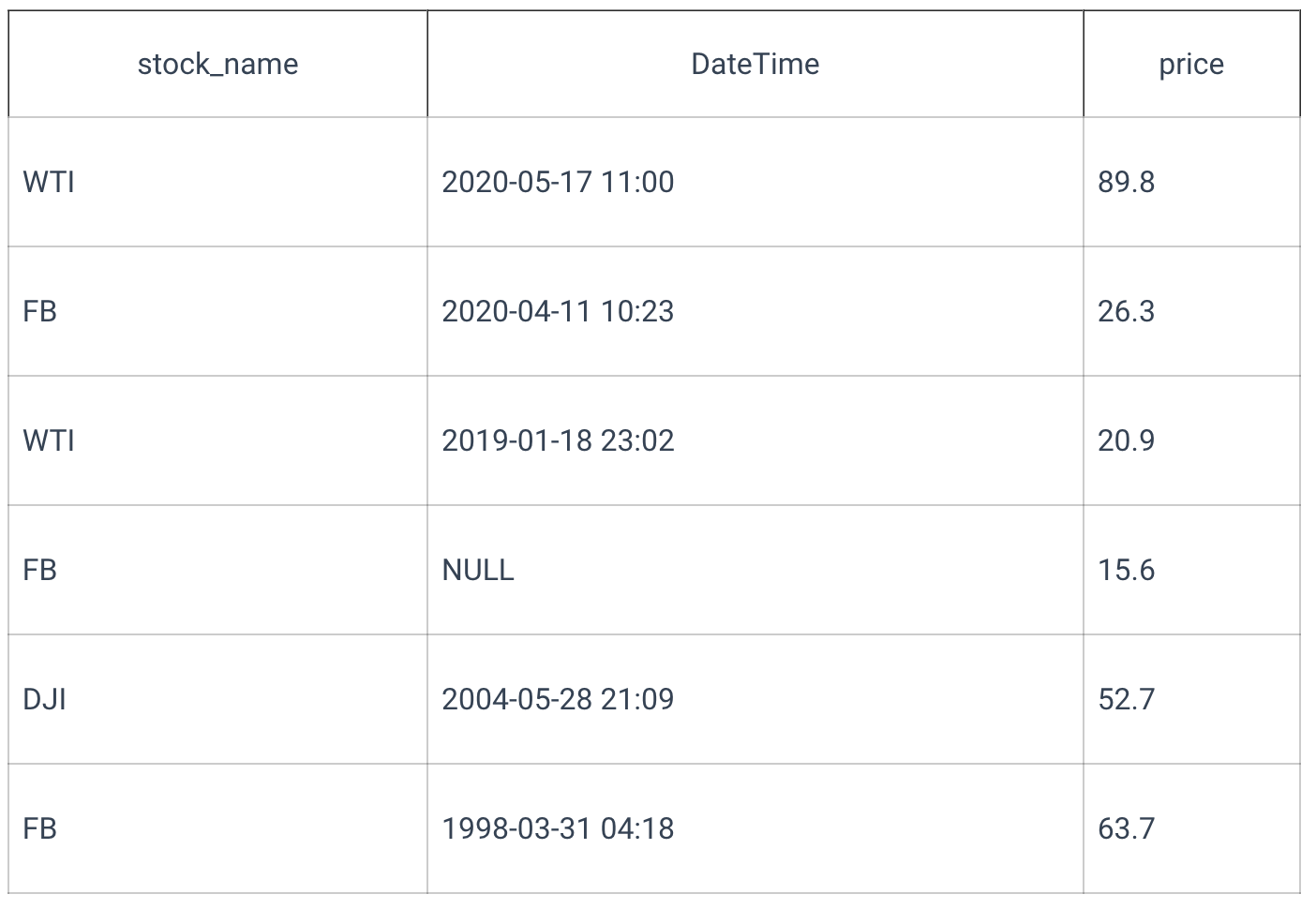
NULL value forms a separate category because it is considered a unique value. Two rows for WTI, 2019-01-18 23:02, merged into one with the maximum price of 20.9. In terms of result, grouping query without any aggregate functions equals to:
If a column is not mentioned in GROUP BY clause and there is at least one aggregate function being used in SELECT, this column can not be used in SELECT portion of the query without being wrapped in an aggregate function.
HAVING keyword
The GROUP BY statement is typically used with the WHERE statement to filter the rows and the ORDER BY to order them. There is another clause that is helpful with grouping tasks–HAVING. If WHERE accepts conditions on values that certain cells have, HAVING does the same but for values of already computed aggregations. To select stock-datetime pairs with a maximum price above 50, the query will look as follows:
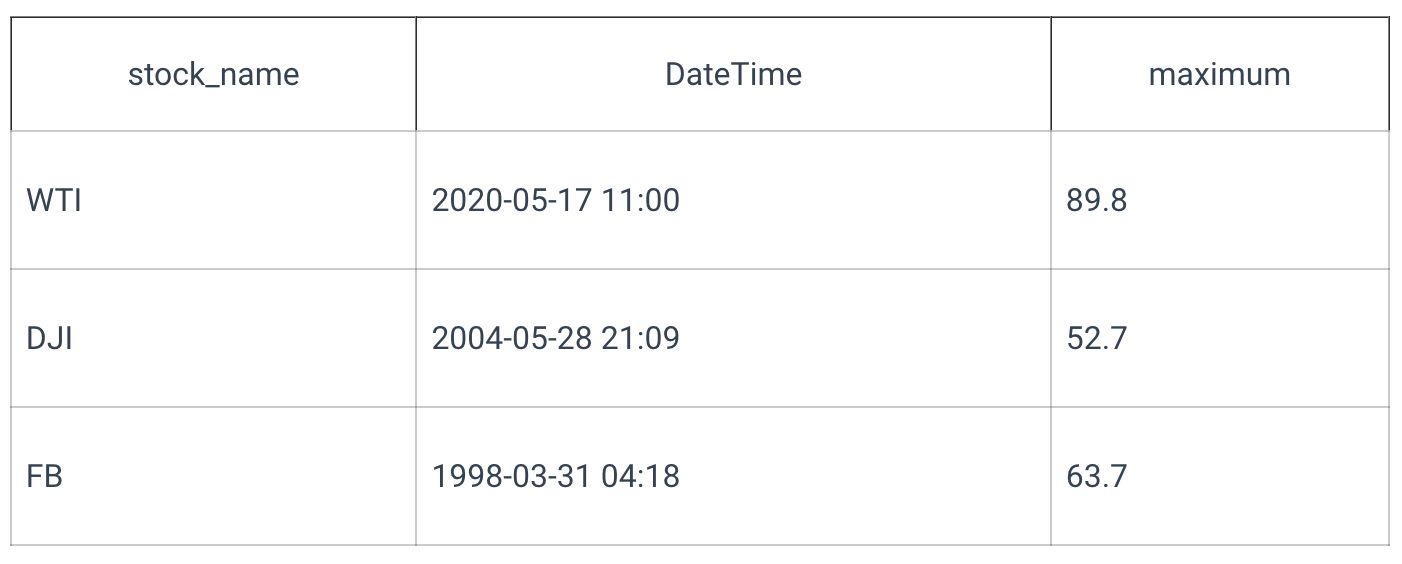
Why can't one utilize WHERE for the filtering? The reason for that is the order of evaluation of the statements:
- FROM
- WHERE
- GROUP BY
- HAVING
- SELECT
- ORDER BY
All the conditions with HAVING have to relate to aggregation functions. Besides that, there are no other special restrictions.
