What is Data Scraping and How to Do It Right
Data scraping is a technique where a computer program extracts a wide range of data from human-readable output (i.e., email addresses) coming from another program. In modern programming, we most often have to implement it when a certain website does not have an API. That's nice, but before we do that, we need to make sure the website owner agrees with it and hasn't banned it.
.webp)
Building a website scraper
In this short article, I will explain how to implement a solution with JavaScript — the common language of the web. I created a website which we will use to target our simple web scraper. This website can be found here.
In fact, it is just a shopping-cart with some content. All the results data and scripts which we will describe you can get from the article GitHub repository.
Our ultimate goal is to get the information about these products in a format that works for us and is easy to get in the future (Google Sheet, for example).
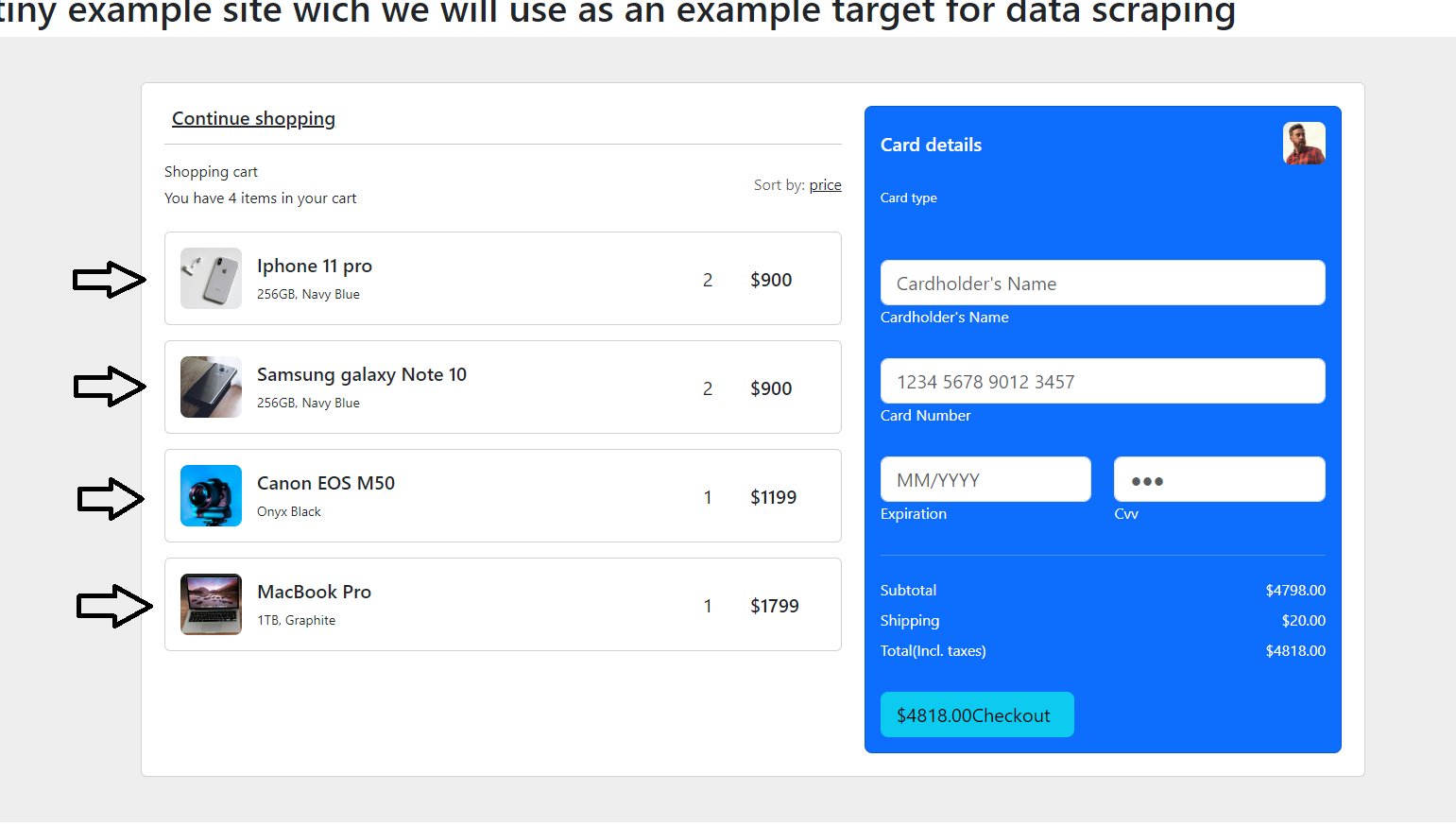
As you can see, every shopping cart item consists of information which we can specify as four properties – name, description, quantity, and price. It will be excellent for us if we can have, for example, a .JSON file with this data, which we can later use to import it into a database. Often, for quick data extraction process, we use frontend scrapers. For our purposes, we can use just plain JavaScript and directly execute it inside the browser console. Here is an example code snippet. You can find this in the article repository. Its name is data-scraper.user.js.
You can also watch a demonstration how it works life on this TikTok video.
With document.querySelectorAll('div.card.mb-3') we receive a NodeList from all these items.
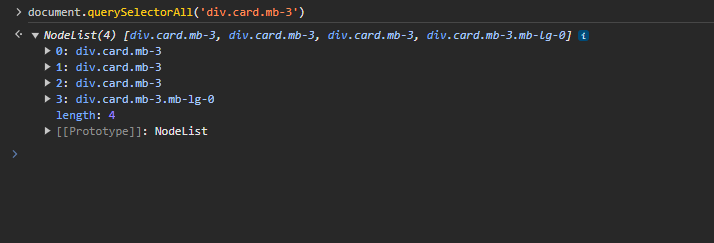
To use the methods on an Array object, we need to convert this NodeList to an object. We achieve this with Array.from which creates a new, shallow-copied Array instance from an iterable or array-like object. After this, we can create a new array which consists of plain objects. In JavaScript, a plain object is a set of key-value pairs, created by the {} object literal notation. Information in web development is usually returned to JavaScript as an array from plain objects in web development. In the map function for every of these DOM objects we use the querySelector method to extract information from his child elements — those below him in the hierarchy. The objects which are returned from map method callback will become items in the new array. In the end, array from plain objects with such structure (see data.json file):
If you paste the script in browser console like this:
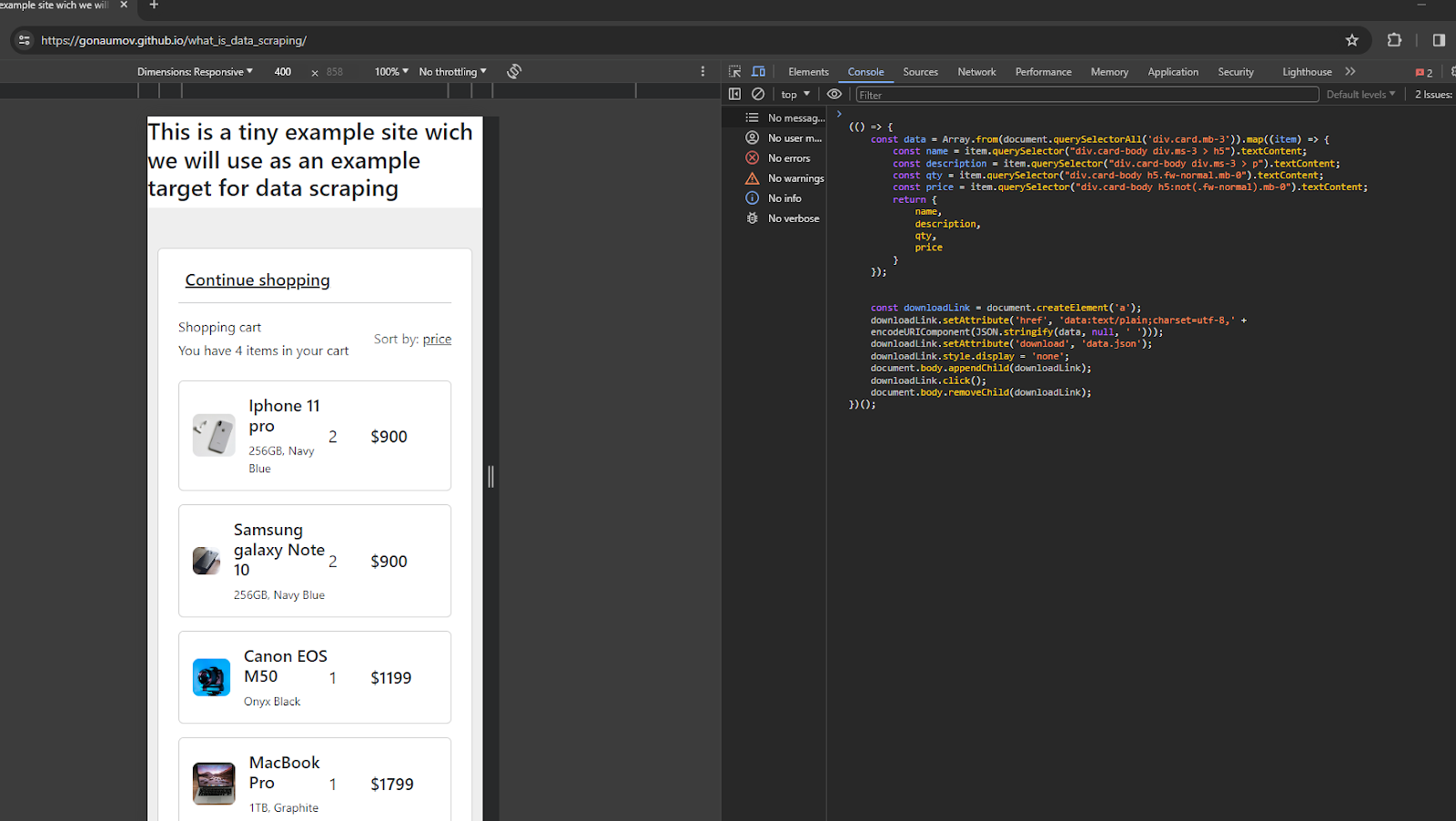
And just press Enter, you will get the result file downloaded to your pc, and you can open it directly. Such an approach is good but has some cons – it cannot be started automatically – for example from cronjobs or pipelines.
Using Puppeteer library solution for scraping
To do it in the right way, we can use npm package scripts, which look almost the same as the front-end one. For this purpose, we will use Puppeteer, which is a Node.js library which provides a high-level API to control Google Chrome/Chromium over the DevTools Protocol. Puppeteer allows us to execute JavaScript on page level, which makes it very useful for scraper tasks. You can watch a demonstration of the whole approach in this TikTok video.
To have Puppeteer installed and to use it from npm first we need to have a npm project which we start with the command npm init. This command will ask you several questions and create a package.json file. Then, when you have a package.json file, you can install Puppeteer with npm i puppeteer. This will create a record in package.json file like this:
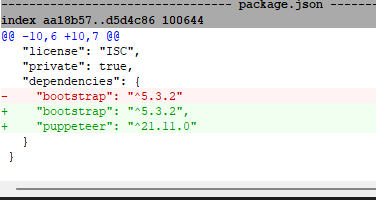
When the project needs to be started on another PC, typing npm install or npm I (the short form) will be enough to provide all the necessary libraries. This is how our NodeJS-based version looks (see node-scrapper.js file).
To be able to run it, you have to specify such a section in the package.json file.
In such a way, you will be able to run it with this command: npm run scrape and to ensure the command will be started from installed inside node modules binaries.
With this snippet, we import needed libraries:
This part is
An IIFE (Immediately Invoked Function Expression) is a JavaScript function that runs as soon as it is defined. By using it, we avoid polluting the global namespace. With using async, we say that in the function we will use await promises. Promises are a very intriguing approach which JavaScript uses to handle asynchronous logic. You can think about Promises as something similar to eggs. An egg can hatch a chicken, can break and nothing happens and to not be still hatched — waiting state. After waiting, we will have chicken or an exception. So we will start the browser:
And wait it until launch.
Then we will go to the website:
And wait until the goods appear:
The interesting part is that Puppeteer has possibility to execute JavaScript on page level and receive the result:
Inside dataItems constant, we will have the needed data structure in the same way as from the pure front-end part. Then we just write the data in the result-data.json, close the page and close the browser. This is how the script output looks:

Conclusion
Data scraping tools are powerful resources that allow users to extract valuable information from various websites and sources. The article provided a practical example using Puppeteer, which is a popular tool for web scraping.
The code snippet demonstrated how to scrape data from a website, specifically retrieving product details such as name, description, quantity, and price. It highlighted the use of JavaScript functions like querySelector and evaluate to navigate the page and extract relevant information.
Overall, data scraping tools offer a wide range of possibilities for collecting and analyzing data from various sources. They can be used for tasks such as email address extraction, screen scraping, content aggregation, and competitor analysis. These tools leverage technologies like optical character recognition, pattern recognition engines, and application programming interfaces to gather data efficiently.
However, it is crucial to consider ethical concerns and adhere to privacy policies while using data scraping tools. It is important to respect the terms of service of the websites being scraped and ensure that the process does not infringe upon user privacy or violate any legal regulations.
If you need any clarification, please let me know. 😊
Related Hyperskill topics
like this
Create a free account to access the full topic

