Database Design 101
Think about any application idea you’d like to implement. Chances are, you’ll eventually need a database, as storing your application data is essential.

Long before choosing the database type, driver, and where to deploy it, you should decide how to organize the data to store it in an efficient, accurate, and maintainable way. This involves the concept of database design; in this article, we will talk about basic things you should know to correctly model your data organization. The principles described in this article are mainly applicable to relational database design.
Understanding Your Data
To start designing a database, you should clearly understand your data from the business requirements side. These are some valuable questions to ask yourself or the business at the start:
- What is the main objective of the application that will use the database? What entities do we store?
The first thing you need to understand is the database scope. What exactly are you storing? How are these objects related to each other? Are there any hierarchies or dependencies? It’s imperative to be as specific as possible here because even a tiny change in the structure may lead to a severe redesign later.
- Who is going to use the data? What are some use cases?
An application might have more than one type of users, and they might need access to different data or manipulate it differently. Write down some primary use cases and think through possible edge cases.
- What are future growth plans for the database?
Another vital piece you should consider in the beginning is how the application might evolve over time and ensure that the database can adapt to future needs. Having an idea of what changes may be required in the future can give you an understanding of the data structure.
When you have answers to those questions, you’re good to go. And it’s time to start designing.
Designing Stage
After you’ve gathered the initial info on your data and decided about the entities you will store, it’s time to divide information into tables. A table is a database term describing a unit storing a separate entity. Each table consists of rows and columns for each data record and each entity property, respectively.
Let’s go with a popular application example that many beginner courses suggest implementing — a simple social media platform. This platform will have the functionality to share posts, comment on those posts, and add users to your network. Let’s design a database for this application.
Defining Entities
When you’ve gone through the questions from the previous paragraph, you might have come up with the following main entities: Users, Posts, and Comments. If we were to design a real-world application, we would also think about the possible user roles — like administrators. But to keep the example simple, we won’t stop here this time and consider our application only to have one type of regular users.
Once we’ve defined the entities, we should continue with the attribute definition. Another important database term is the primary key. This is the unique property (or a column) every table must have — it identifies the data record. So don’t forget to add this attribute to each model. Keeping that in mind, we might determine those fields:
- For the Users entity: User ID, Username, Password, Email, and Registration Date.
- For the Posts entity: Post ID, Content, Creation Date, Likes Count, and User ID (to associate the post with its creator).
- For the Comments entity: Comment ID, Content, Creation Date, Post ID (to associate the comment with the post), and User ID (to identify the comment author).
Note that the primary key must always be present in a model, meaning the value chosen as the primary key cannot be nullable or empty. This is why we normally create a separate explicit ID field for this purpose. However, in some cases, for example, for the Users table, a `username` could also make a good primary key.
It is useful to have a visual representation of your database at this point. And database design has an approach for it, too. It’s called an Entity-Relationship Diagram (often referred to as ERD), and it’s widely used to visualize the database structure. An ERD is not only helpful in the planning and designing stage, but it will also serve as documentation. Especially as your database grows bigger, it will be much more convenient to have a complete picture right in front of you.
At this point, we have the following layout:
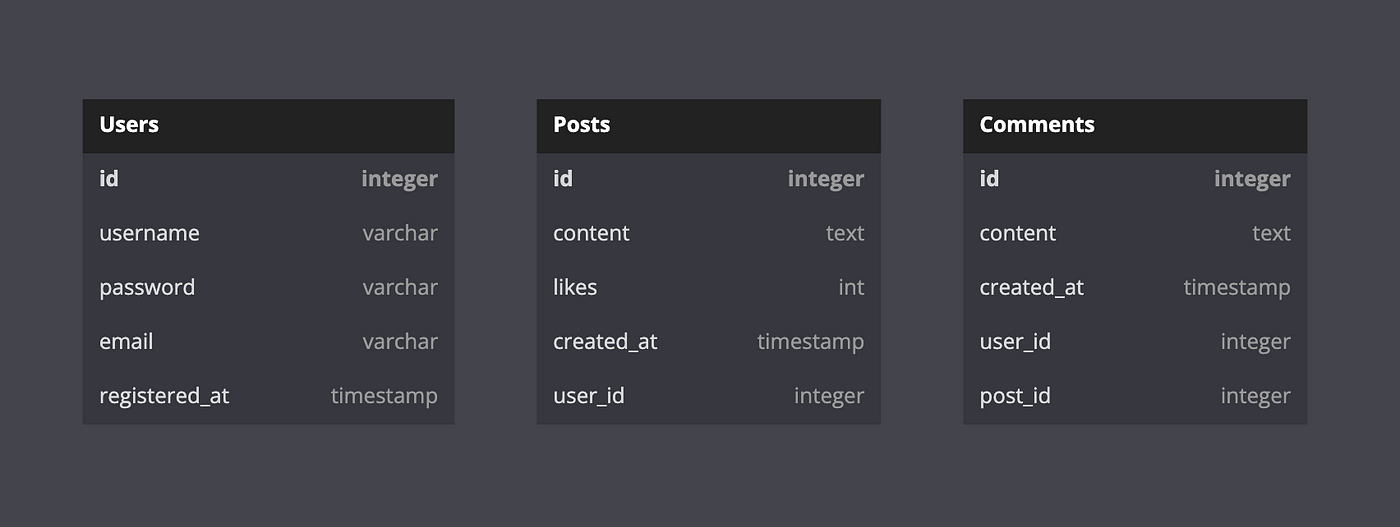
There are multiple online tools for drawing ERDs. I used https://dbdiagram.io/ for this article. You can read more about creating ER diagrams here.
Establishing Relationships
A relational database is called relational for a reason. The entities we define are usually related, and you need to analyze and implement those relationships accurately. Things you would need to recognize at this stage:
- What tables are related?
- What kind of relationships are these? For example, can users have multiple posts? Can a post have multiple users?
- What are the keys that will connect the entities?
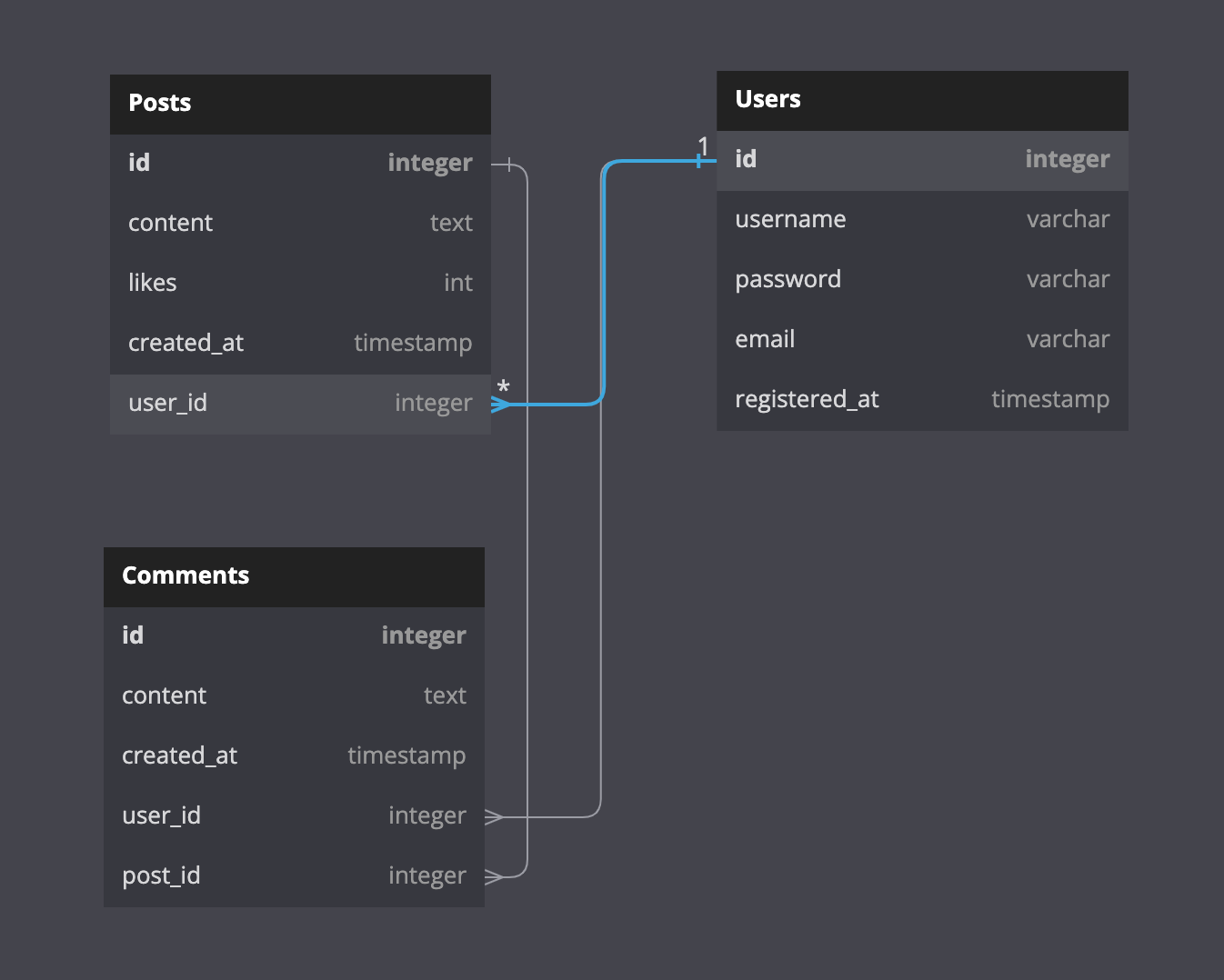
In our case, we can tell that posts are related to users, and comments are related to both posts and users. Every one of them has a primary key. And when a primary key appears in another table to define a connection, it is called a foreign key.
This is how these relationships would appear on our ER diagram:
The relationships between entities are classified into three types:
- One-to-One Relationship (1:1)
In a one-to-one relationship, each record in one entity is associated with exactly one record in another, and vice versa. For example, if later you would like to store the user’s profile picture as a separate table entity, the relationship between Users and ProfilePictures would be one-to-one because a user cannot have more than one profile picture, and the same profile picture (as an instance) cannot be used by multiple users.
- One-to-Many Relationship (1:N)
In a one-to-many relationship, a record in one entity is associated with multiple records in another entity. Still, each record in the second entity is associated with only one record in the first entity. In our project, an example of a one-to-many relationship would be Users and Posts or Posts and Comments.
- Many-to-Many Relationship (N:N)
In a many-to-many relationship, multiple records in one entity can be associated with multiple records in another. A good example of this kind of relationship in the social media platform would be friendships — i.e., Users to Users.
Wait, but how do we connect entities for many-to-many relationships? In the project description, we mentioned that we would want our users to have relationships — like friending, following or blocking. But if you look closely, the diagram doesn’t have it defined. Yet.
To implement a many-to-many relationship, you need to create an additional table containing the primary keys of both entities you want to connect and, optionally, some additional data. To relate the Users in our example, that’s what this table could look like:
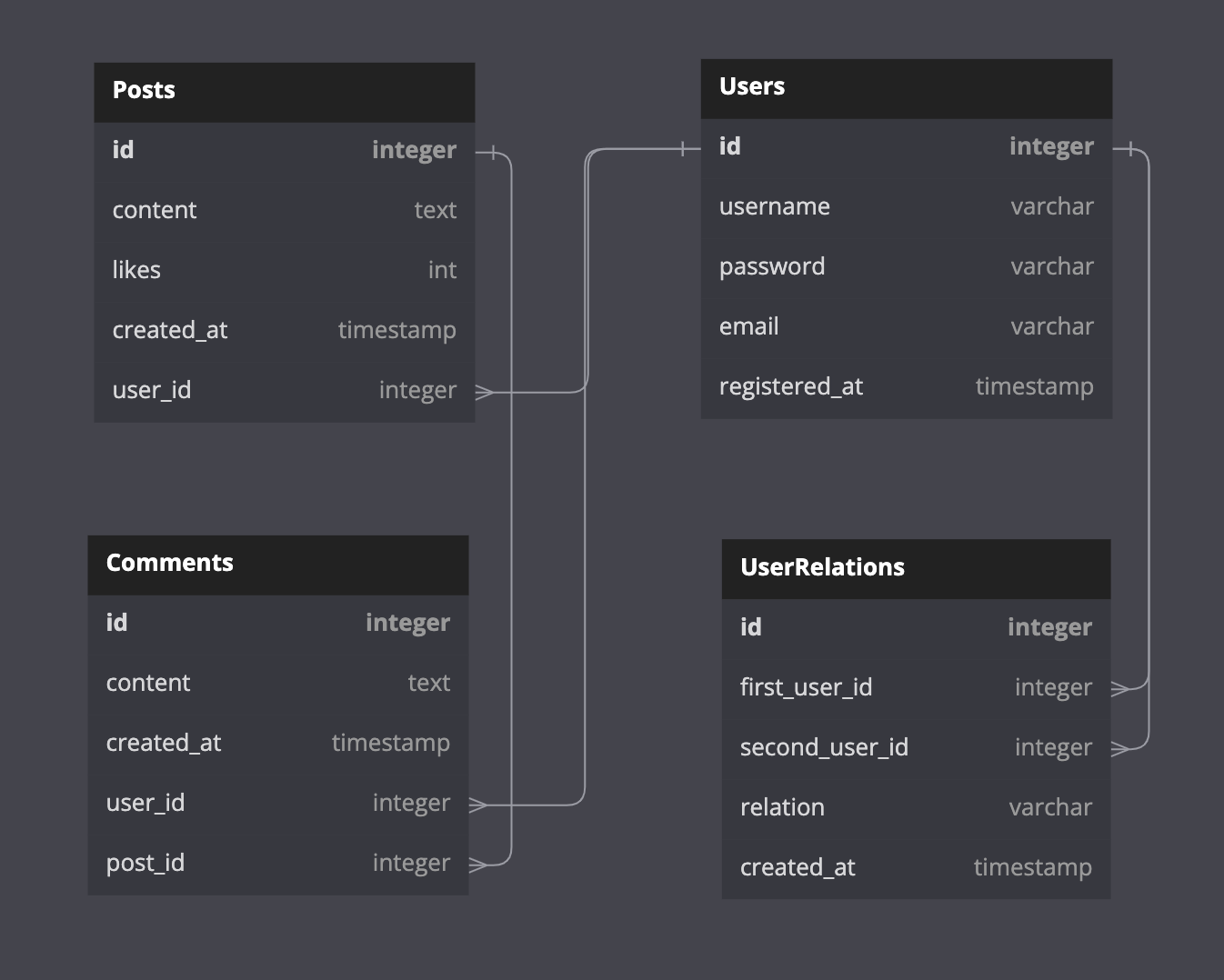
The new UserRelations table has two one-to-many relationships with the Users table, containing two Foreign Keys for users we want to establish a connection between.
We also added two fields — created_at to keep track of a specific user’s relations and relation to save the relation type. This will allow us to store friendships, follows, and blocks within the same table and add more types of user relations later. Note that the relation field type is varchar on the diagram. However, in some cases, you would probably want to have it as an enum, limiting the variety of values that can be put in that column.
Rules and Constraints
And that leads us to defining constraints in designing a database. It’s not enough to just determine the fields and their types. Establishing guidelines and restrictions on the data stored in the database is also crucial, as it helps maintain data consistency, integrity, and accuracy.
Constraints are rules defined at the table level to ensure that data entered into the database meets specific criteria, such as uniqueness or data domain. You’ve already met some of the constraints in this article — the Foreign/Primary Key constraints. Once you mark a table field as a Primary Key, the database will control and prevent invalid data from being inserted into this field. Another widely used constraint is the Unique constraint. You can tell from the name that when it’s added to a field, it ensures that the values inserted into the property are unique over the table. For example, we could put a Unique constraint on the `email` field in the Users table to ensure a user can register a specific email only once.
In the previous paragraph, we discussed the `enum` data type. Although it’s not a constraint, it’s commonly used to define a specific set of values that are authorized on the database level. This makes it an effective tool for maintaining data integrity.
Remember about the Default rules, too, as they are often defined in the designing stage. Defaults are values assigned to a column or attribute in a database table if no explicit value is provided during data insertion. For instance, a “created_at” column in the Posts or Comments table can have a default value of the current timestamp, so if no date is provided during data insertion, the current timestamp will be automatically assigned as the default value.
These rules are not always defined on the database level. Sometimes moving them to the application code is beneficial for flexibility and customization. For example, the enum values can be defined on the application level if you expect a set of values to change in the runtime. Even though defining constraints is mostly preferable to do in the database, the final decision depends on the specific requirements, environment, and trade-offs in your particular case.
Database Normalization
Once your initial design is ready, you can apply data normalization rules to your database to ensure your tables are structured correctly. Applying the rules to your database design is called normalizing the database or just normalization.
These rules are aimed at efficient data separation, without unnecessary duplication, and to minimize the risk of data inconsistencies or anomalies. There are six normalization rules or Normal forms, each building upon the previous one. Describing them all in detail and with examples is going to be a whole new article, but let’s briefly mention the basics to get the main idea. The most commonly used normal forms are the first three:
- First Normal Form (1NF): Ensures atomicity by stating that every table field (or a cell) should contain only one value and never a list of values.
- Second Normal Form (2NF): Builds upon 1NF and ensures that each non-key attribute fully depends on the primary key.
- Third Normal Form (3NF): Extends 2NF by removing transitive dependencies, requiring non-key attributes to depend only on the primary key, not other non-key attributes.
Data normalization is a valuable tool as it eliminates redundancy, improves data integrity, and makes it easier to manage data efficiently in relational databases. Let me know in the comment section below if you want to see an article on data normalization from me, and we will dive into the topic next time.
Conclusion
In this article, we’ve reviewed the fundamental principles of database design in the very early stages. Effective database design requires understanding data requirements, analyzing relationships and dependencies, enforcing data integrity with constraints, and normalizing data structures. Remember, these skills are only polished with practice, so I highly recommend going through this post’s example or repeating the actions with some other application idea.
If you want to go further with the social media platform example, consider expanding your database. At this moment, likes on posts are anonymous. If you decide to have a list of people who liked the post, you should consider introducing a new “Likes” entity, a table to contain information about a user and the post they liked. Or will it be a “Reaction”? What would change in the table structure, then?
If you want to learn more and get some practice with databases, Hyperskill is a great place to continue your adventure. Here are some topics you might want to check out:
Hyperskill also has various topics on handling database interactions from different programming languages. If you are learning or want to learn Python, check out Flask track and, specifically the Movie Database API project that focuses on practicing database design.
Hyperskill is a project-based learning platform that offers a personalized curriculum and a variety of tracks to help people from different backgrounds gain market-relevant skills through online education. It’s giving you solid pieces of theory and allows you to practice the skills right away — and practice makes learning perfect.
Did you find this post helpful? Hit clap and follow to read more of them later :)
like this
Create a free account to access the full topic

